Population Estimates at the Start of the Decade
Population Estimates at the Start of the Decade
Estimated reading time: 11 minutes
The start of each decade at the U.S. Census Bureau is marked by the collection and release of census data, providing a fresh account of the size and characteristics of the U.S. population. These updated population numbers enable researchers, community planners and others to use the most current data in their work.
We at the Census Bureau’s Population Estimates Program (PEP) count ourselves among these data users. We eagerly anticipate the results of the census as a once-a-decade benchmark for gauging the quality of the annual population and housing unit estimates products. (More information on how demographic data may be compared to the 2020 Census results can be found in a recent blog). The census counts also serve as a new base from which we build the next decade’s postcensal estimates.
Developing a new base for our postcensal estimates series may be the most notable update to the PEP estimates at the start of the decade, but it’s not the only difference between our pre- and post-2020 Census estimates. In this blog, we explore the various changes in the upcoming estimates series featuring data for July 1, 2021, known as Vintage 2021.
Background
PEP is responsible for producing annual population estimates for many levels of geography including the nation, states, metropolitan and micropolitan statistical areas, counties, cities and towns, as well as Puerto Rico and its municipios. For counties and higher levels of geography, we also produce estimates by demographic characteristics: age, sex, race and Hispanic origin.
Typically, we develop the estimates beginning with the latest decennial census as the base. For counties and higher levels of geography, we then add or subtract current data on births, deaths and migration (i.e., the components of change) to the base population to reflect annual change. This approach is known as the “cohort-component method.”
Each year, we release a time series of data that starts with the most recent census year and includes annual estimates up to the latest year of data available, also known as the “vintage year.” For example, our last series of estimates was Vintage 2020, which started with the 2010 Census as the base. We then used data on births, deaths and migration to create estimates of the population for 2010 through 2020.
Challenges for the Vintage 2021 Estimates Base
It follows, then, that the base population for the Vintage 2021 estimates would have been the 2020 Census. However, PEP encountered several challenges in establishing the Vintage 2021 base population.
Prior to 2020, PEP was aware that Census Bureau efforts to comply with its statutory confidentiality obligations by modernizing its disclosure avoidance system would mean that certain variables used for processing the estimates based on the 2010 Census would not be present in the relevant internal confidential 2020 Census data files. Among them: the identification variable that associates records with a specific address, and the race variable featuring the categories in the PEP data.
In addition, the COVID-19 pandemic delayed census operations which added a degree of uncertainty regarding when data would become available for PEP’s use.
For context, prior to incorporating input data sources (e.g. births, deaths, migration, etc.) into estimates production, PEP regularly evaluates the data for suitability. However, these delays and uncertainty regarding the schedule did not make it possible to apply these best practices to the 2020 Census data. Subsequently, we were unable to use these data by the full demographic detail that we had used in previous vintages.
To ensure we could meet the deadline for publishing the estimates and still meet our high data quality standards, we needed a new way to derive a base population without relying exclusively on decennial census data.
As a result, we created a “blended base” that supplements national, state and county totals from the 2020 Census Public Law 94-171 redistricting file with other sources of PEP data to achieve the highest accuracy possible. These sources of estimated population data for Census Day (April 1, 2020) were the Vintage 2020 estimates and the 2020 Demographic Analysis (DA) middle series.
The Vintage 2020 estimates used the 2010 Census as a base. But unlike other sources, the Vintage 2020 estimates included the full level of detail we needed to produce Vintage 2021 estimates (for instance, race, Hispanic origin, single year of age and sex detail down to the county level).
The 2020 DA estimates, on the other hand, are entirely independent from the census because they are produced from administrative records. These estimates used vital records, such as birth and death certificates, as well as data on international migration to determine how many people were expected to be living in the United States on April 1, 2020. DA features three data series (high, middle and low) based on different assumptions about the population to determine a range of plausible estimates.
The 2020 DA estimates were released before the 2020 Census results and serve as a benchmark against which to assess coverage in the census (that is, how well the Census Bureau did at counting everyone in the nation). DA estimates are only available at the national level, but we believe the DA data by single year of age and sex, limited race and Hispanic origin are highly accurate. For the purposes of the blended base, we ultimately only incorporated the age and sex detail at this time because DA estimates do not include all race groups, and the Hispanic origin estimates are limited to ages 0 to 29.
The blended base took advantage of the most accurate and unique aspects of each of these data sources.
- We used national, state and county totals from the 2020 Census.
- DA’s middle series provided the national age structure and sex distribution, which we then used as a control for the lower levels of geography.
- Vintage 2020 estimates filled in the remaining gaps, particularly race and Hispanic origin. We also used proportions from the Vintage 2020 estimates to split the total resident population into its household and group quarters population components.
Figure 1 illustrates the blended base process.
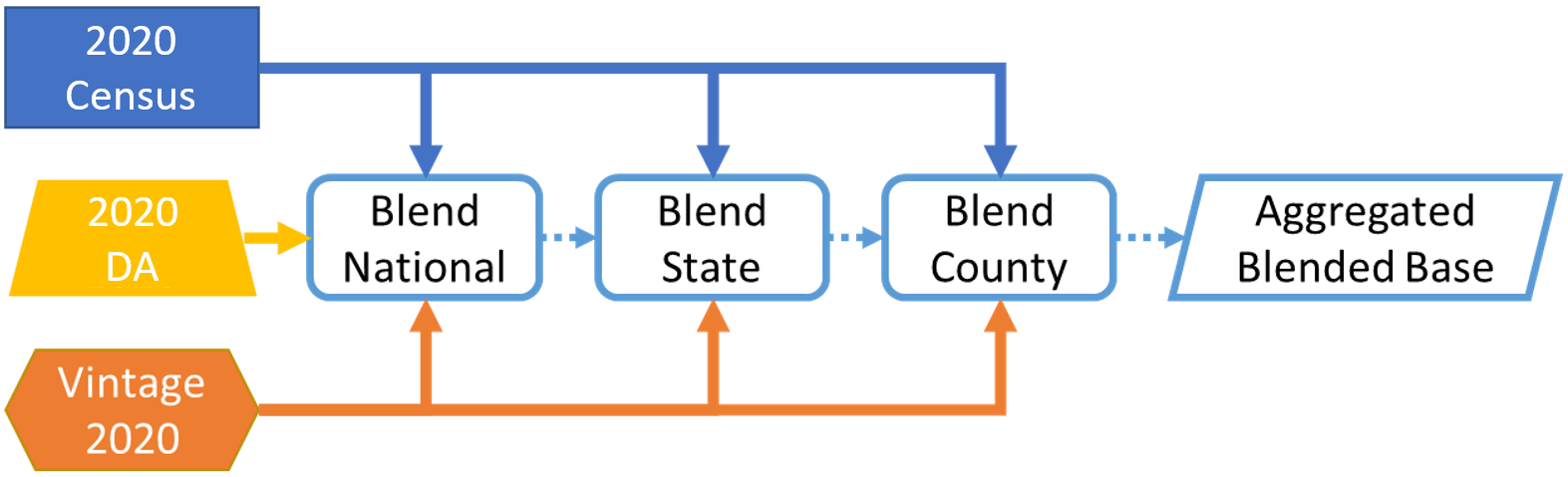
We also had to change how we develop the base population for our estimates for subcounty geographies (i.e., cities and towns). We will describe these changes in more detail closer to their scheduled May 2022 release.
Updates to the Estimates Components
In addition to adapting how the population base is created, we examined whether it was necessary to adapt how we estimate annual change to that base via births, deaths, domestic migration, international migration and change in the group quarters population.
Births
In a typical vintage of estimates, there is a two-year lag in the National Center for Health Statistics (NCHS) data we use to estimate births. We usually try to compensate for this gap by using provisional totals as well as data from our state partners in the Federal-State Cooperative for Population Estimates (FSCPE), which help us get some limited information for the year prior to the vintage year.
For Vintage 2021, the first year of the time series is 2020, which means our typical process would not work since the last year of final birth data we have is 2019 (an issue that is regularly encountered in the first series of estimates to follow the census). To address this issue, we used NCHS’ provisional monthly totals from 2020 and applied the full detail characteristics distribution from 2019 to them. This creates a year of data in which the monthly totals match the 2020 NCHS provisional data but the characteristics of the data (sex, race and Hispanic origin) match the 2019 final NCHS data. For 2021, we estimated total births from both historical patterns and provisional data.
In the end, we had births by full demographic detail for the year 2020 and the total number of national births for 2021 to use in estimates processing. Since this approach used the NCHS provisional total births for the period when the COVID-19 pandemic occurred, our input data reflected changes in the birth rates during the pandemic.
Deaths
Like the birth data, there is also typically a two-year lag in the death data we receive from NCHS. To estimate deaths for 2020, we used an approach similar to the one we used for the births. We incorporated 2020 provisional monthly death totals and applied the distribution of final 2019 demographic characteristics to them. The result was a time series of 2020 deaths by age, sex, race and Hispanic origin for the nation.
By using the total monthly deaths for 2020, we were able to incorporate data that included the excess mortality from the pandemic. We were also able to include provisional death totals to estimate the first two quarters of 2021, so the final Vintage 2021 estimates capture the national-level impacts of the COVID-19 pandemic up to July 1, 2021. Subnational data were sparser, so no subnational adjustments were made other than controlling the subnational deaths to the national-level data (which includes the pandemic effects).
Domestic Migration
Our program measures net domestic migration by using a combination of data from the Internal Revenue Service (IRS), Medicare enrollment, the Social Security Administration, and the decennial census. Since the available 2020 Census data do not contain the information needed to assign race and ethnicity to migrants, we continued to use 2010 Census reported race and Hispanic origin in processing.
A big focus in Vintage 2021 was assessing whether our method had to be adapted because of the impact of COVID-19 on migration patterns and our input data sources. To make this assessment, we evaluated whether tax filing extensions granted during the pandemic affected the IRS data we use. We also compared the patterns of domestic migration in the IRS data with other sources, such as the U.S. Postal Service’s National Change of Address database. After a thorough review, we determined there was no need to include an adjustment to our usual method of measuring net domestic migration to account for the COVID-19 pandemic.
International Migration
In a typical year, when estimating net international migration, we heavily rely on data from the Census Bureau’s American Community Survey (ACS). However, the pandemic had a substantial impact on the collection of the 2020 ACS. As a result, we relied on data from other sources, including the U.S. Department of Justice, Department of Homeland Security (Citizenship and Immigration Services), State Department (Bureau of Consular Affairs and Refugee Processing Center) and the Institute of International Education, to calculate an adjustment to apply to the 2019 ACS estimates.
To measure net migration between Puerto Rico and the rest of the world, we utilized airline passenger traffic data from the Bureau of Transportation Statistics. Moving to a flight data-based method improved the accuracy and timeliness of net migration estimates for Puerto Rico, better reflecting the impact of the pandemic on recent migration patterns.
Change in Group Quarters Population
Part of the estimates process is to measure change in the group quarters (GQ) population since the last census. However, for Vintage 2021, there was a delay in the availability of GQ data from the 2020 Census, so we made the group quarters data part of the blended base project. Simply put, the 2020 GQ base is derived from the blended base by using proportions from the Vintage 2020 estimates and applying them to the blended-base resident population.
When producing the estimates in a normal year, we work with our FSCPE partners to gather information on annual change in GQ populations. To that end, we consulted with the FSCPE and then determined the most empirically sound approach was to hold the population levels in the April 1, 2020, estimates base constant into 2021, resulting in no GQ change between 2020 and 2021. When more data become available on the pandemic’s impact on the GQ population, we will be able to reevaluate our approach.
Looking Ahead to Vintage 2022
We recently discussed many of the changes to our methodology in a webinar, and invite you to watch the recording or download the slides.
Although we’ve finalized the Vintage 2021 methodology, there is still considerable uncertainty affecting the direction we will take for our Vintage 2022 estimates. In particular, the timeline for receiving additional 2020 Census data, such as the Demographic and Housing Characteristics File, will exert the greatest influence on the options for our Vintage 2022 estimates base. To use additional detail from the census, we must first conduct a comprehensive analysis to verify the data are sufficient for our use in the Vintage 2022 estimates base at the fine level of detail we require for processing. Naturally, it will take time to determine this.
Our intent is to use coverage measures such as DA and the results from our robust internal Estimates Evaluation (E2) project to examine differences between Vintage 2020 estimates and the census results. This evaluation will be complex, and the results will indicate whether there are any specific geographies or characteristics that could introduce challenges if they are included in the estimates base.
Similarly, the results should reveal whether there is additional detail from the census that could be incorporated into future iterations of the blended base. Over the coming months, PEP analysts will use DA and E2 to determine what a Vintage 2022 blended base would look like.
The blended base for Vintage 2021 is the outcome of a major collaborative research endeavor in PEP that also involved other Census Bureau experts and numerous external stakeholders at various junctures in its development. It provides a novel approach to addressing the complexities introduced by the COVID-19 pandemic and enterprise disclosure avoidance modernization, and an adaptive framework that positions us to continue to meet the needs of our data users over the course of the decade.