
Independent Census Bureau Population Estimates Will Help Assess Accuracy of the 2020 Census
On Dec. 15, the U.S. Census Bureau will release Demographic Analysis estimates of the U.S. population.
Eric Jensen, senior technical expert for Demographic Analysis at the Census Bureau, explains what Demographic Analysis is and how it serves as an integral and independent early assessment of the accuracy of the 2020 Census.
Why does the Census Bureau produce Demographic Analysis (DA) estimates?
Since 1960, the Census Bureau has used Demographic Analysis every 10 years to estimate the size of the nation’s population, using April 1 as the reference day just like the decennial census. The estimates are released in December prior to the results of the census as a comparable measure to that count.
One of the things the DA shows is the potential overcount or undercount in the census by age, sex, the DA race categories and Hispanic origin for cohorts born after 1990. In doing so, it highlights coverage patterns in the census throughout the decades.
Demographic Analysis was originally developed by demographers at Princeton University to estimate coverage error in the 1950 Census. The Census Bureau started using it to evaluate the 1960 Census and has been doing so ever since.
Even though we have improved the data and methods used to produce the DA estimates, the overall approach — taking birth records and subtracting deaths, adding immigration and subtracting emigration — remains the same.
We release DA estimates before we know the 2020 Census counts to show that the Census Bureau is committed to providing quality data, and that we hold ourselves accountable for our results.
How does the Census Bureau use DA?
DA is used in two ways. First, the results are compared with the census counts to identify groups that may have been overcounted or undercounted in the census. We can review coverage patterns by age, sex and the DA race categories.
The two DA race categories are Black Alone and non-Black Alone, and Black Alone or in Combination and non-Black Alone or in Combination. For cohorts born after 1990, we can also estimate coverage by Hispanic origin.
This figure is a great example of how the DA estimates can show differential coverage patterns in the census. The graph shows that coverage in the decennial census has improved dramatically since 1960, but there are still large differences between the non-Black population and the Black population, especially for Black adult males.
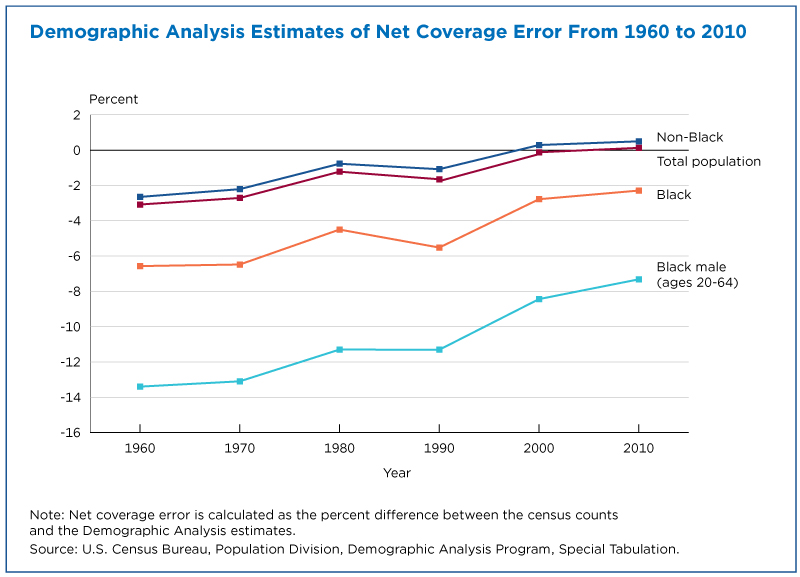
Second, some estimates from the DA are used as inputs for the Census Bureau’s other measure of the quality of the census, the Post-Enumeration Survey (PES).
For some age and sex groups, the PES uses DA estimated sex ratios to adjust for what is called “correlation bias.” Correlation bias is error that is caused when groups that are missed in the census are also missed in the PES.
The PES results will be available starting in November 2021 and will enable the Census Bureau to estimate coverage errors by additional population groups and for the 50 states, the District of Columbia, and Puerto Rico, as well as for various census operations.
What should we know when comparing DA and census results?
DA estimates are an independent coverage measure, meaning that we did not use any information from the 2020 Census to produce the DA estimates. The estimates are only a benchmark to help us understand the quality of 2020 Census data.
The U.S. Constitution mandates that we count the population every 10 years, and this information is used to inform apportionment as well as help determine how hundreds of billions of dollars in federal funding is distributed to communities around the country. The DA results are estimates of the population and not a person-by-person count like the census.
DA cannot be used to replace the census and is not used for apportionment or to determine funding. We release DA estimates before we know the 2020 Census counts to show that the Census Bureau is committed to providing quality data, and that we hold ourselves accountable for our results.
It’s important to remember that DA does not offer the same level of geographic and demographic detail as the decennial census, as the estimates are only produced at the national level. The census results include national, state and local numbers, down to the block level.
In addition, there are limitations to the race and ethnic detail in the DA estimates. The race information in birth and death records has changed dramatically over the decades.
In 1945, the published birth records only included two categories, White and non-White, while the most recent birth records include more detailed race categories: American Indian or Alaska Native, Asian, Black or African American, Native Hawaiian or Other Pacific Islander, White and more than one race.
What is the relationship between DA estimates and the 2020 Census, annual population estimates and the Population Clock?
DA uses current and historical vital records, data on international migration and Medicare records to develop estimates of the population on April 1, 2020. We start with birth records in 1945 and account for deaths and international migration to the people born in that year all the way until 2020. We do this for all birth cohorts from 1945 to 2020.
The census is not an estimate. The census counts the nation’s population by collecting responses from households through a questionnaire.
While a lot of the same data and methods are used to make the DA estimates and the official population estimates that the Census Bureau releases every year, they are very different.
The official population estimates typically use the most recent census as a base and account for population change since the last census. For example, the Vintage 2019 population estimates start with the 2010 Census and account for births, deaths and migration until July 1, 2019 (“Vintage” refers to the final year of the time series.)
Lastly, the population clock is based on a series of short-term projections created from monthly estimates from the latest vintage of official population estimates.
Since DA is a coverage measure, is it able to tell us if people were counted once, only once, and in the right place?
DA is used to produce national estimates of net coverage error. Because it is a net measure, net coverage error cannot separately measure the people who were missed and the people who were counted more than once. In addition, because DA estimates are only available at the national level, we are not able to determine if people were counted in the right place.
The strength of DA is what it tells us about the age and sex patterns of net coverage error in the decennial census. For example, in 2010, DA showed that the largest net undercount rates were for young children ages 0 to 4. We have a lot of confidence in this because the DA estimates for those ages come primarily from birth records, which are very complete.
PES will produce separate estimates of the number of people that were missed or counted more than once in the 2020 Census. PES will also include state-level estimates of coverage error. However, these results won’t be ready until November 2021.
Will DA estimates be a preview of what will be released in the 2020 Census counts?
The (most recent) DA results are an estimate of the U.S. population on April 1, 2020 that is independent of the census. So, while we use it as a comparison tool for the quality of census results, it should not necessarily be seen as the precursor to those results.
In 2010, the middle series of the DA estimates was about 300,000 less than the total census count, implying a very slight overcount in the 2010 Census. However, in 2000, the initial DA estimates were several million less than the census counts, while the PES was several million higher than the census.
Census staff ultimately determined that the initial DA had underestimated immigration during the 1990s. After correcting for this, the Census Bureau then released an updated, final DA estimate that was about 400,000 higher than the Census 2000 count, implying a small undercount of 0.12%.
What does it mean if the DA estimates are different from the census?
Differences between the DA estimates and the census counts can mean that either the census or DA is incorrect. Ideally, the estimates can give us a good idea of the groups that were overcounted or undercounted in the census.
But the differences could also be indicative of error in the DA estimates, although we do a lot to ensure that the estimates are accurate. Census Bureau staff have effectively been working on the 2020 DA estimates since we finished the 2010 DA estimates. In 2018, we enlisted some of the top demographers in the country to work with us to determine which data and methods are best to use.
We also produced a range of estimates to account for any errors in the data or methods.
Why does the Census Bureau release a range of estimates?
We produce a range of estimates — low, middle and high — to account for uncertainty in the data and methods used to create the DA estimates.
Administrative records on births and deaths are very complete, so we do not estimate a lot of uncertainty for these components. These adjustments account for only approximately 20% of variance in the final range of estimates.
The largest share of uncertainty in the range of DA estimates, nearly 40%, comes from the estimates of the foreign-born population. We expected this given the data and methods that are available to produce estimates of this population. International migration of the native population accounts for around 10% of the variance of the range of estimates. Unlike births and deaths, people can migrate more than once during their lifetime and data on this population is often limited and lacking.
Finally, we use Medicare enrollment records to estimate the oldest population, but some people are ineligible to enroll in Medicare, delay enrollment or never enroll. To account for under-enrollment, we make an adjustment in the Medicare numbers. For the range, we vary that adjustment to give us a low, middle and high estimate. This accounts for the remaining 30% of variance.
Together, these variances are used to create the range of estimates to give us a measuring stick for the nation’s population as of April 1, 2020.
Why are estimates only available at the national level?
Birth records are the foundation of DA estimates. We could use birth records to assign everyone to their birth county and state, but this would not account for any migration from one geography to another throughout their lifetime.
For example, I was born in Idaho but have lived as an adult in three other states. The data or methods to accurately produce county or state-level estimates for all ages are just not available. That’s why the strength of DA is what it tells us about the age and sex structure of the nation’s population as a whole.
Why are DA estimates broken down by Black/Non-Black only? What about other races?
For 2020, we used birth and death records from 1945 to 2020. Because race information is very limited on older records, we are limited in the amount of race detail that we can provide.
Historically, DA has produced estimates by two broad race groups: Black Alone and non-Black Alone. In 2010, we also developed estimates of the Black Alone or in Combination and non-Black Alone or in Combination population for ages 0 to 29. For 2020, we have expanded these estimates to be available for ages 0 to 85 and above.
The DA estimates by Hispanic origin are a good example of how we can’t produce DA estimates for other race and ethnic groups. Hispanic origin was not included on the birth certificates for all states until 1990. For 2020, we were able to produce the Hispanic/non-Hispanic DA estimates for people born after 1990, or ages 0 to 29 on April 1, 2020, but we do not have the data to produce estimates for older cohorts by Hispanic origin.
We also plan to produce DA estimates for the population ages 0 to 18 by additional race detail in what we are calling an “experimental series” in 2022.
How has DA changed over the past decades?
We are always making improvements to the data and methods used to produce the DA estimates. For 2020, the biggest difference from past decades is how we are estimating the foreign-born population.
Migration is hard to estimate because we do not have good administrative records like the vital records that come from birth and death certificates. That is, a person is only born once or only dies once, but people can migrate multiple times throughout their lifetime.
In the past, we tried to measure international migration flows — immigration and emigration — which is challenging because we don’t have very good data on emigration. Nor do we have very good historical data which is required to capture the potential for people to migrate multiple times throughout their life.
For 2020, we would have had to measure migration flows from 1945 to 2020. We decided instead to use a stock method, which estimates the foreign-born population at a single point in time. We took the foreign-born stock population in the 2019 American Community Survey and projected it forward to April 1, 2020.
We made some other adjustments as well. This estimate accounts for all immigration, emigration and deaths to the foreign-born population, making it much easier than trying to estimate various migration flows over 75 years.
Even though we made this big change for 2020, the real driver for the DA methods is still birth records, which hasn’t changed. Birth records continue to be the foundation for the DA estimates.
-
Stats for Stories*Special Edition* World Statistics Day 2020: Oct. 20, 2020Every five years on Oct. 20 we celebrate how innovation drives the U.S. Census Bureau to create new and improved data products to better serve our customers.
-
Stats for StoriesWorld Population Day: July 11, 2026The U.S. Census Bureau’s International Database projects the world population will reach 8.2 billion this year and 9 billion in 2039.
Subscribe
Our email newsletter is sent out on the day we publish a story. Get an alert directly in your inbox to read, share and blog about our newest stories.
Contact our Public Information Office for media inquiries or interviews.
-
America Counts StoryHow We Develop and Improve the CensusJuly 31, 2019Randomized experiments and carefully planned evaluations help improve the census.
-
America Counts StoryNation’s Population Growth Slowed This DecadeApril 06, 2020See how your state’s population changed over the decade in an interactive visualization recently released by the U.S. Census Bureau.
-
America Counts StoryNew Tool for Discovering Nation's Demographic Past, Present and FutureMarch 25, 2020Seven decades of Census Bureau publications provide a window into America’s changing demographic landscape.
-
PopulationU.S. Fertility Continues to Drop but Still High in Some CountiesJune 25, 2026Counties with the highest numbers of births have some of the lowest fertility rates.
-
TaxationFundamental Shifts in State Taxes in Past CenturyJune 17, 2026Income and sales taxes have largely replaced property taxes, once the lion’s share of state tax revenue.
-
HousingHelping You Decide Where to Buy a HomeJune 10, 2026Census Bureau resources help homebuyers find the best locations for their needs.
-
Population2026 World Cup Teams Will Have Home Crowds Among U.S. Foreign-BornJune 09, 2026Census data show which of the 48 countries in the World Cup have the largest foreign-born fan bases in the United States and where they live.